RocksDB use case
This use case aims at identifying the root cause for high tail latency at client requests issued to RocksDB.
The instructions to reproduce the use case are available at how to reproduce, while an extended set of visualizations provided by DIO is available at portfolio.
Problem
As shown in Figure 1, RocksDB suffers from high tail latencies, where clients observe several latency spikes (e.g., ranging between 1.5 ms to 3.5 ms).
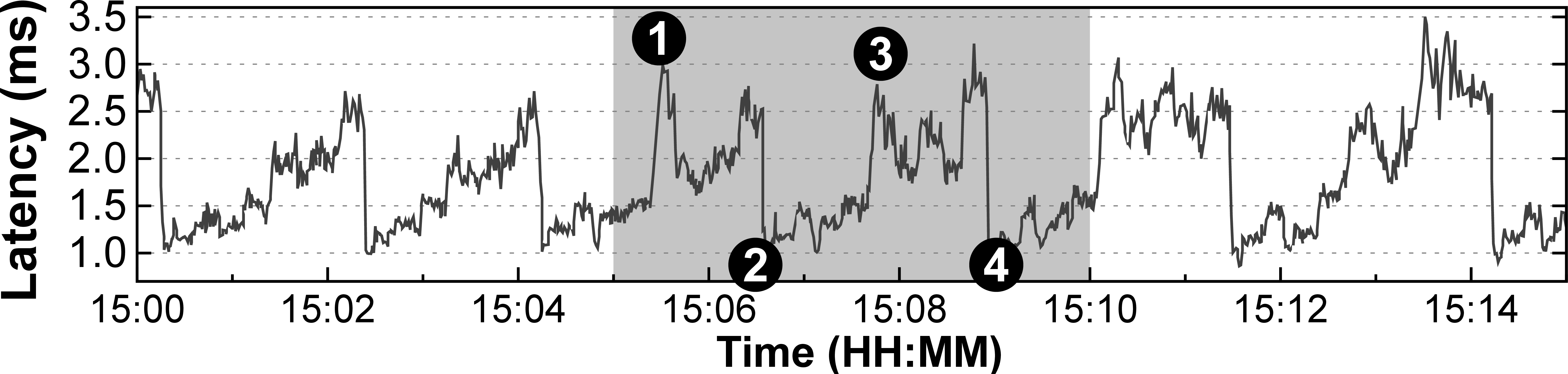
Figure 1. 99th percentile latency for RocksDB client operations.
Diagnosis
By using DIO to observe the system calls submitted over time by different RocskDB thread groups, one can identify performance contention. Namely, as shown in Figure 2 by the highlighted red boxes, when multiple compaction threads submit I/O requests, the number of system calls of db_bench threads decreases, causing an immediate tail latency spike perceived by clients (1&2). When fewer compaction threads perform I/O (black boxes), the performance of db_bench threads improves, both in terms of tail latency and throughput (3&4).
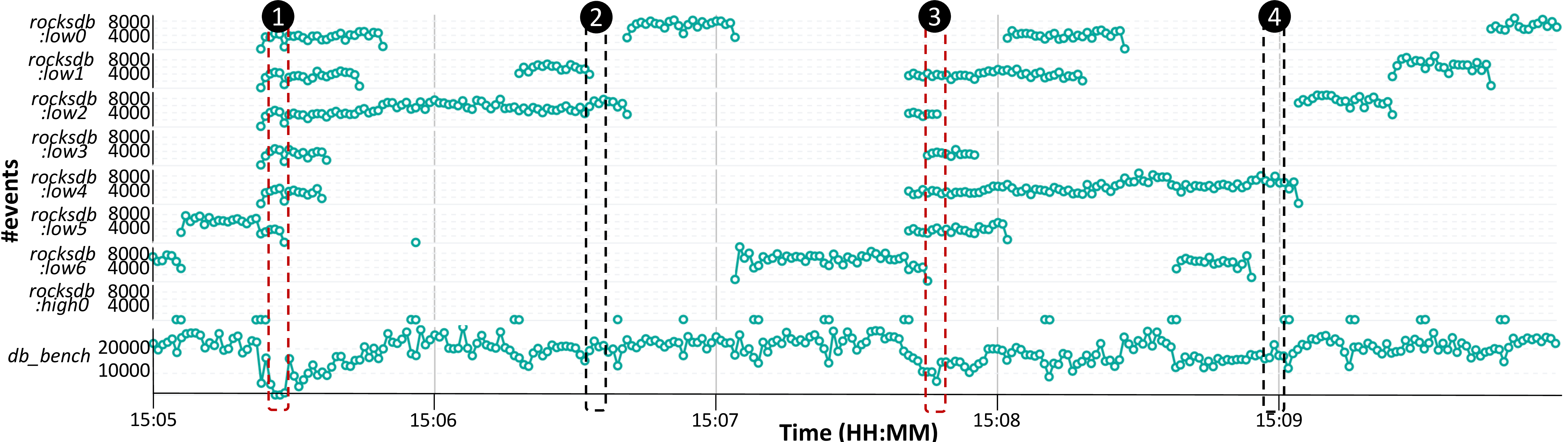
Figure 2. System calls issued by RocksDB over time, aggregated by thread name.
db_bench includes the 8 client threads, rocksdb:low[0-6] refers to each compaction thread, and rocksdb:high0 refers to the flush thread
Explanation
RocksDB uses foreground threads to process client requests (db_bench threads), which are enqueued and served in FIFO order.
In parallel, background threads serve internal operations, namely flushes (rocksdb:high0) and compactions (rocksdb:lowX).
Flushes ensure that in-memory key-value pairs are sequentially written to the first level of the persistent LSM tree (L0), and these can only proceed when there is enough space at L0.
Compactions are held in a FIFO queue, waiting to be executed by a dedicated threadpool.
Except for low level compactions (L0 →L1 ), these can be made in parallel.
A common problem of compactions however, is the interference between I/O workflows, generating latency spikes for client requests.
Specifically, latency spikes occur when client threads cannot proceed because L0→L1 compactions and flushes are slow or on hold, which happens, for instance, when several threads compete for shared disk bandwidth (creating contention).